Interview: TrustNShare – Partizipativ entwickeltes, Smart-contract basiertes Datentreuhandmodell mit skalierbarem Vertrauen und Inzentivierung : Datum:
Im nachfolgenden Interview sprechen Prof. Dr. Cord Spreckelsen (Gesamtprojektleitung „TrustNShare“ und Arbeitsgruppenleitung Medizinische Informatik, Universitätsklinik Jena), Dr. Sven Amaru Bock (Teilprojektleitung „TrustNShare“, DLR) und Dr. Friederike Klan (Abteilungsleitung „Data acquisition and mobilization“, DLR) über die zentralen Ergebnisse des Projektes und schildern ihre praktischen Erfahrungen bei der Konzeption und Umsetzung von Datentreuhandmodellen.
Welches Problem wollen Sie mit Ihrem Datentreuhandmodell konkret lösen? Welchen Bedarf versuchen Sie, damit zu adressieren? (Auf Seiten der Datengebenden wie Datennutzenden)
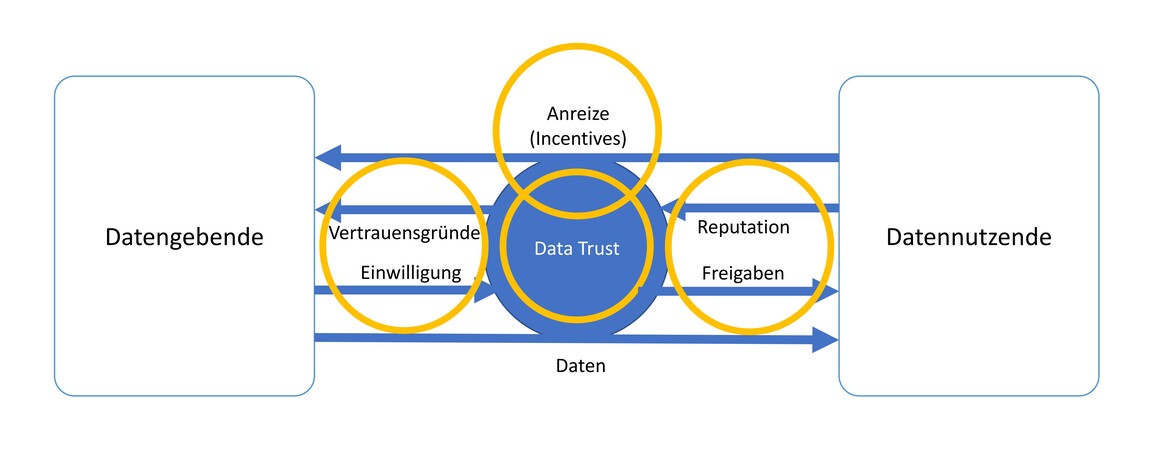
Datentreuhänderschaft spielt eine Schlüsselrolle zur Inzentivierung, zur Qualitätssicherung und für den Datenschutz beim Teilen von Daten. Ausgangspunkt von TrustNShare ist, dass einige Datenschutzverfahren es erlauben, das Schutzniveau frei zu wählen, also einzustellen, wie hoch das Risiko ist, dass der Bezug von den Daten zu einer Person wiederhergestellt werden kann (das Re-Identifizierungsrisiko). Einem hohen Schutzniveau steht dann aber oft ein stärkerer Eingriff in die Daten, z. B. stärkere Verallgemeinerung, gegenüber. Daten werden dann weniger aufschlussreich und weniger nützlich für die Datennutzenden. Ähnlich abgestuft, wie das Schutzniveau, kann auch die Reputation der Datennutzenden ausfallen – von ausgezeichneter Vertrauenswürdigkeit bis zu niedriger. Vor diesem Hintergrund geht es in TrustNShare darum, möglichst flexibel das Schutzbedürfnis der Datengebenden, ihre Ansprüche an die Vertrauenswürdigkeit der Datennutzenden, die Ansprüche an die Datenqualität seitens der Datennutzenden und deren Bereitschaft, Anreize zu geben, in ein Gleichgewicht zu bringen. Das soll auch technisch unterstützt werden.
Re-Identifizierungsrisiken merkmalsreicher Datensätze führen dabei zur besonderen Herausforderung, dass sich inzwischen die harte Grenze zwischen datenschutzpflichtigen Daten mit Personenbezug und anonymen Datensätzen immer mehr auflöst. Allerdings erlauben gerade im datenintensiven Bereich des maschinellen Lernens etablierte Verfahren wie Differential Privacy oder Distributed Privacy Preserving Computing einen fein justierbaren Informationsfluss, d. h. die flexible Wahl des Grads der Datenfreigabe und damit verknüpft: des Re-Identifizierungsrisikos. An die Stelle einer binären Entscheidung für vs. gegen die Freigabe von Daten tritt das graduelle Tolerieren von größeren vs. kleineren Re-Identifizierungsrisiken. Idealerweise sollten Datengebende ihre eigene Risikotoleranz flexibel und kontextabhängig an einen Vertrauenszuwachs bzw. -abbau anpassen können. Hier setzt das Projekt TrustNShare an. Ziel ist die Entwicklung eines Datentreuhandmodells, welches eine transparente Feinabstimmung von Vertrauenswürdigkeit, Risikotoleranz und Datenfreigabe unterstützt.
Welchen Ansatz verfolgen Sie hinsichtlich des Geschäftsmodells/Betriebsmodells Ihres Datentreuhänders?
In TrustNShare steht nicht das Geschäftsmodell/Betriebsmodell einer eigenständigen Datentreuhandinstitution im Mittelpunkt. Stattdessen geht es darum, das partizipativ entwickelte Modell zur Abstimmung zwischen Datengebenden und Datennutzenden durch eine App, den Trust-Navigator zu unterstützen. Die Plattform unterstützt gezielt den Aushandlungsprozess der zu für beide Seiten vorteilhaften Datennutzungskontrakten führt. Diese werden auf der Grundlage feingranularer Präferenzen des Datennehmenden hinsichtlich des Teilens sensibler Daten sowie der durch den Datennehmenden angebotenen Incentives und dessen Reputation konstruiert. Ihre Umsetzung wird manipulationssicher protokolliert. Das eigentliche Geschäftsmodell zielt auf Beratungs- und Customizing-Services zur und ggf. Lizensierung der im Projekt entwickelten technischen Plattform.
Welche Governance-Struktur streben Sie an? Wie sollen Entscheidungen bezüglich des Datenzugangs, der gemeinsamen Nutzung und der Nutzungsrichtlinien geregelt werden?
Es werden individuelle Datennutzungskontrakte zwischen Datennutzenden und Datengebenden mittels der TrustNShare-Plattform vorgeschlagen, geschlossen und manipulationssicher protokolliert. Die Entscheidung bezüglich des Datenzugangs erfolgt, wenn die Bedingungen an Reputation, Datenschutzniveau und spezifische Anreizfaktoren erfüllt sind, von welchen die Datengebenden ihre Einwilligung zur Nutzung ihrer Daten abhängig gemacht haben.
Anhand des Protokolls kann nachgewiesen werden, unter welchen Bedingungen der Datenzugang gewährt wurde. Es kann auch nachgewiesen werden, welche Qualitätsanforderungen – bezogen auf die Effekte des Schutzniveaus – die Datennutzenden an die Daten gestellt haben. So sind manifeste Abweichungen von der vereinbarten Datennutzung klar definiert und können rechtlich beurteilt werden.
TrustNShare sieht allerdings keine vollständige Automatisierung der Datentreuhandservices vor.
Die Verifikation der Datenqualität auf der einen und reputationsrelevanter Auskünfte der Datennutzenden auf der anderen Seite müssen institutionell verankert und verantwortet werden.
Auf welcher technischen Basis funktioniert Ihr Datentreuhandmodell? Welche Strukturen und Instrumente werden dafür genutzt?
Wir nutzen Standard-Web- und Datenbanktechnologie (http-Server, Dokumentenbasiertes Datenbankmanagementsystem – konkret node.js express und mongoDB für das Backend und React für das Frontend) unter Verwendung von etablierten Verfahren der Transportverschlüsselung. Das Web-Backend wird containerbasiert aufgesetzt und betrieben auf einer Docker-Platform. Als wichtige technische Komponente umfasst die technische Basis des Datentreuhandmodells die manipulationssichere Transaktionsprotokollierung in einer Blockchain. Hierfür werden Hyperledger Fabric und Hyperledger Firefly eingesetzt.
Wie wollen Sie das Vertrauen der Datengebenden und Datennutzenden gewährleisten, gerade auch vor dem Hintergrund möglicher Datenschutzbedenken?
Nach einer umfassenden Analyse empirischer Befunde bezüglich der (subjektiven) Befürchtungen Datengebender in Bezug auf das Teilen von Aktivitätsdaten thematisieren, wurden in einer weiterführenden Recherche Anreize erarbeitet, welche die Bereitschaft der Datengebenden für das Teilen ihrer Daten erhöhen sollen. Auf Basis dieser Recherchen wurde eine Fragebogenstudie konzipiert und durchgeführt, um die internationalen Befunde auf nationaler Ebene zu verifizieren. Hieraus resultierten folgende empirische Befunde:
Die Datenspendenden wünschen sich Transparenz und Kontrolle über ihre geteilten Daten. Sie möchten Einblick in das Datenmanagement, klare Informationen über den Verwendungszweck ihrer Daten sowie darüber, wer die Daten erhält. Einfach gestaltete Benachrichtigungen sind ihnen wichtig. Zudem möchten sie entscheiden können, welche Daten weitergegeben werden und an wen, einschließlich der Granularität der Datenfreigabe. Die Mehrheit bevorzugt eine Opt-In-Lösung für die Einwilligung zur Datenweitergabe und legt großen Wert auf Anonymisierung, um eine Re-Identifizierung zu vermeiden. Aus diesem Grund entwickeln wir mit der Trust-Navigator-App ein benutzerfreundliches Interaktionswerkzeug für Datengebende und Datennehmende, welches die genannten Bedürfnisse adressiert.
Mit Hilfe der Trust-Navigator-App wird die Kommunikation zwischen Datengebenden und Datenempfängern in anonymer Form ermöglicht. Hierbei haben die Datengebenden die Möglichkeit, im Rahmen eines Reputationsmodells ihre Erwartungen, Bedingungen und ggf. Kompensationswünsche anzugeben. Diese Voraussetzungen werden anschließend vom Trust Center mit den Angeboten und Profilen der Datenempfänger abgeglichen, um den Datenspendenden zu ermöglichen, ihre Daten mit den Institutionen zu teilen, die ihren Anforderungen und Voraussetzung am besten entsprechen. Wie bereits beschrieben, werden dann alle Transaktionen, die sich auf den Datenaustausch beziehen manipulationssicher in einer Blockchain protokolliert. Die Identität der Beteiligten ist dabei unter Nutzung von Public-Private-Key-Verfahren so verborgen, dass eigene Transaktionen zwar zugeordnet, eingesehen und verifiziert werden können, für die übrigen Transaktionen der Bezug auf Personen oder Institutionen jedoch verborgen bleibt.
Welche bemerkenswerten Erfolge oder Meilensteine wurden bei der Entwicklung Ihres Datentreuhänders erreicht?
Auf Basis unserer empirischen Befunde konnten wir ein Reputationsmodell zur Einschätzung der (subjektiven) Vertrauenswürdigkeit Datennehmender entwickeln. Darüber hinaus wurden Anreize konzipiert, welche mögliche Risiken beim Teilen sensibler Daten kompensieren sollen und so das Teilen von Daten befördern.
Auf dieser Basis wurde dann unser Transmissionsmodell konzipiert und umgesetzt. Das Transmissionsmodell fragt danach, in welcher Höhe potenzielle Datennutzende Anreize für welche Datenqualität – bezogen auf datenverändernde Maßnahmen zum Schutz vor Re-Identifizierung – setzen würden. Es fragt auch welche Kompensationen für Re-Identifizierungsrisiken die Datengebenden erwarten. Das kann natürlich nicht für jede der sehr vielen unterschiedlichen Einstellmöglichkeiten des Datenschutzniveaus erfragt werden. Ein wichtiger erreichter Meilenstein ist es, dass wir ein Transmissionsmodell konzipieren konnten, das eine – auch entscheidungspsychologisch begründete – Berechnung erwarteter Kompensationen, bzw. angebotener Anreize je Schutzniveau erlaubt, wenn die Erwartung bzw. Bereitschaft für einige wenige ausgewählte Schutzniveaus erfragt wurde. Das Transmissionsmodell rechnet also die fehlenden Zwischenwerte hoch.
Gibt es Herausforderungen oder Hindernisse, die während des Prozesses aufgetreten sind? Falls ja, wie sind Sie damit umgegangen?
Konzeption und Entwicklung eines Datentreuhänders sind eine interdisziplinäre Aufgabe. Eine Herausforderung bestand darin, empirische Forschung und technische Entwicklung im Projektgut aufeinander abzustimmen und eine gemeinsame Kommunikationsebene zu finden. Dies ist bisher durchaus gut gelungen, durch Workshops und regelmäßige Treffen und nicht zuletzt durch die große Offenheit und Zugänglichkeit aller Projektbeteiligten.
Was hat Sie bei der Entwicklung Ihres Datentreuhänders am meisten überrascht?
Bei der Auswertung der Fragebogenstudie ergaben sich teilweise überraschende Ergebnisse: In dem Fragebogen wurden die Probanden gebeten abzuschätzen, welche Aktivitätsdaten Daten von entsprechenden Geräten aufgezeichnet werden. Darüber hinaus wurde in einer weiteren Frage die Bereitschaft zum Datenteilen erfasst. Wir gingen davon aus, dass die Bereitschaft, Aktivitätsdaten zu teilen, mit der vermuteten Anzahl der aufgezeichneten Datenarten negativ korrelieren würde. Hintergrund dieser Annahme war es, dass Personen die davon ausgehen, dass eine hohe Anzahl von Daten erfasst wird, weniger gewillt sind diese Daten zu teilen als Personen, die von einer niedrigen Anzahl von Daten ausgehen. Diese These konnte jedoch nicht bestätigt werden.
Wie stellen Sie sich die künftige Wirkung und Skalierbarkeit Ihres Datentreuhänders vor? Was sind Ihre Pläne für weitere Forschung, Zusammenarbeit oder den Praxiseinsatz?
Das Geschäftsmodell konzentriert sich auf Beratungs- und Customizing-Services zu unserem Datentreuhandmodell und ggf. die Lizensierung der entwickelten Software. Ein weiteres Ziel ist es, unsere Forschung zu den Themen Vertrauensbildung in Datentreuhändern und Anreizen fortzusetzen und auf andere Anwendungsdomänen zu übertragen.